事件驱动架构在生成式AI中的运用
- 应用场景名称
事件驱动架构在生成式AI中的运用
- 应用场景描述
生成式AI的基本原理是通过深度学习技术对大量文本、图像、音频和视频等多模态数据进行学习,构建得到描述自然语言和其他数据的复杂统计模型。此类模型的训练数据几乎涵盖了互联网中的所有信息,参数量巨大,大语言模型(Large Language Model,LLM)是其中的典型代表。这类模型所生成的连贯语句,并非真正“理解”了语言,而是通过复杂的数学计算推断出最可能的词汇或句子结构,最终生成自然流畅的文本输出。这种过程依赖于模型对大量数据的学习,预测得到输出结果。
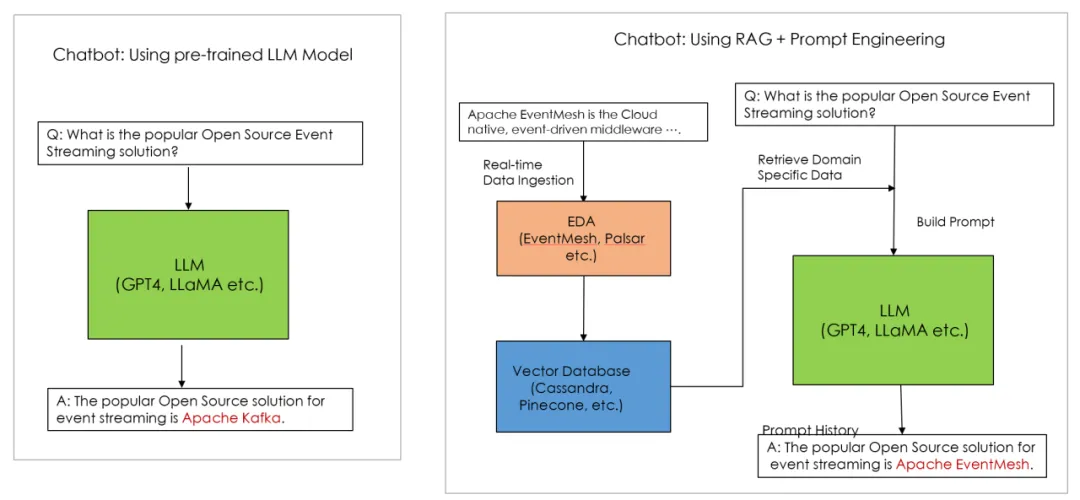
生成式AI依赖的大型语言模型(LLM)需要持续更新训练数据,以确保其生成的内容能够反映最新的语言使用和信息。然而,通常开源的LLM模型在专业领域数据(Domain-Specific Data)方面存在局限。这些数据往往属于特定行业或企业内部,未公开于互联网,因此模型无法获取并学习这些信息,从而在处理专业领域的问题时表现较为有限。
- 应用场景实施方案
为了解决这样的问题,AI领域专家利用Retrieval Augmented Generation (RAG) + Prompt Engineering 的方法,实时向LLM模型输入领域特定数据 (Domain Specific Data) 让LLM利用到最新的数据产生回答。而 EventMesh 的事件驱动机制与RAG高度兼容,能够让数据实时同步到LLM的向量数据库(Vector Database),从而使LLM基于新知识产生更准确的回答,构建实时性生成式AI (Real-time Generative AI)。
除此之外,EventMesh 的 Event Source 和 Event Sink 支持多种事件源和事件目标,适配不同类型的数据源无论是企业内部数据,还是外部公开数据,都可以通过事件驱动系统同步给到LLM的向量数据库,实现LLM数据的多样化。
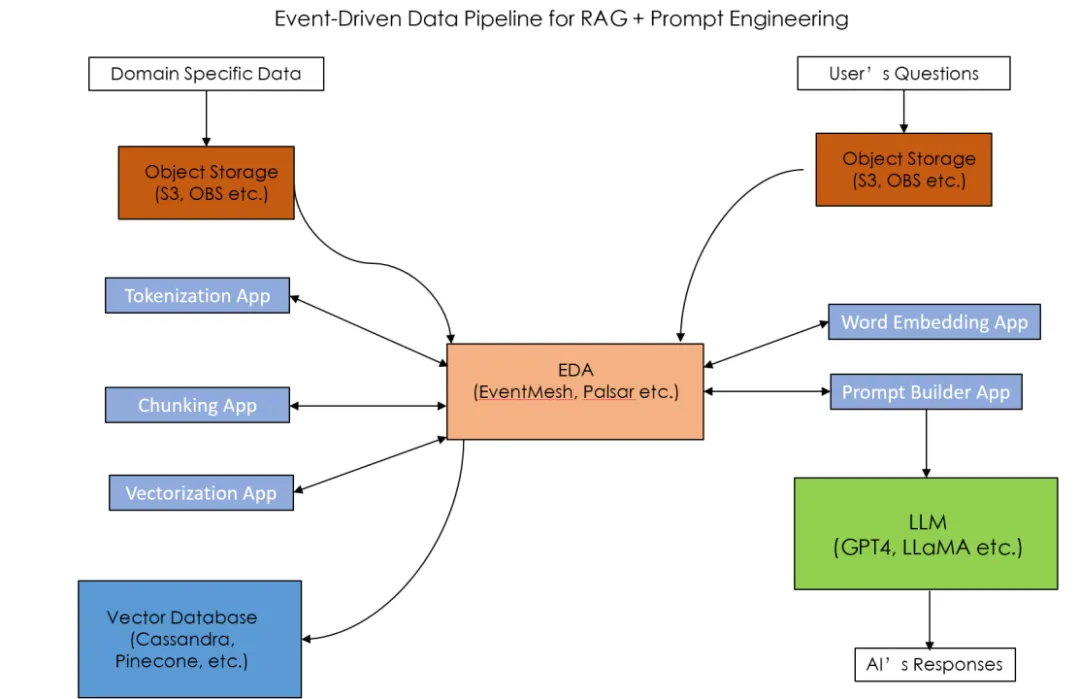
事件驱动架构也增强了生成式AI应用的韧性和可扩展性。RAG + Prompt 工程的方法需要建立由多个微服务组成的数据流水线(Data Pipeline)来处理领域特定数据。数据流水线的主要部分包括Tokenization,Data Chunking,Data Vectorization,Word Embedding 和 Prompt Builder。 这些微服务之间的交互可以通过事件驱动方式异步通信。随着数据量的增大,每个微服务可以独立自动扩容,而不影响整个数据流水线的架构。如果系统想要增加新的微服务,比如构建一个User Feedback App来处理用户反馈数据,则可以通过消费和发布指定Topic跟Data Pipeline其他微服务交互,无需修改其他微服务的接口。EventMesh 的 Serverless Workflow 事件流特性可以用来构建这样的数据流水线。
EventMesh社区和Apache其他开源项目社区将一起持续地探索生成式AI领域新的应用场景。EventMesh架构的Workflow,Event Source / Sink 特性可以帮助构建生成式AI应用,提高AI应用的实时性与准确率,同时增强应用的可扩展性,打造出实时的云原生生成式AI应用。
- 参考资料